- Home
- Hochschule
-
Studium
- Studienangebote
-
Beratung
- Studienorientierung
- Zentrale Studienberatung
- Studienfachberatung
- Psychosoziale Beratung
- Studienfinanzierungsberatung und Stipendien
- Schreibberatung
- Studieren mit beruflicher Qualifikation
- Studieren mit ausländischen Zeugnissen
- Studieren mit Handicap
- Studieren mit Familie
- Informationen für Schulen
- Auslandsaufenthalt
-
Bewerbung
- Auswahlgrenzen und Vergabeverfahren (NC)
- Bewerbungsportal
- Bewerbung Schritt für Schritt: Von der Bewerbung bis zur Einschreibung
- Bewerbung für ein höheres Fachsemester
- Bewerbung mit beruflicher Qualifikation
- Gasthörerschaft und Zweithörerschaft
- Kontakt Studierendenservice
- Losverfahren
- Promotion
- Sonderanträge
- Studiengang wählen
- Wer kann an der HSBI studieren?
- Studienstart
-
Studium organisieren
- Studierendenservice
- Abschlussunterlagen
- Anerkennung von Leistungen
- Anträge einreichen
- Beurlaubung
- CampusCard
- Einreichung schriftliche Arbeiten
- Exmatrikulation
- IT-Services
- Online-Serviceportale (LSF/CAT)
- Prüfungsangelegenheiten: Ordnungen, Modulhandbücher
- Rücktritt von einer Modulprüfung
- Rückmeldung
- Semesterbeitrag
- Semesterticket (Studi-Deutschlandticket)
- Semester- und Vorlesungszeiten
- Studienbezogene Auslandserfahrung
- Studiengebühren
- Vorlesungsverzeichnis
- Rund ums Studium
- Fachbereiche
- Forschung
- Transfer
- Weiterbildung
- Internationales
- Karriere an der HSBI
- Hochschule
- Studium
- Studium
- Studienangebote
-
Beratung
- Studienorientierung
- Zentrale Studienberatung
- Studienfachberatung
- Psychosoziale Beratung
- Studienfinanzierungsberatung und Stipendien
- Schreibberatung
- Studieren mit beruflicher Qualifikation
- Studieren mit ausländischen Zeugnissen
- Studieren mit Handicap
- Studieren mit Familie
- Informationen für Schulen
- Auslandsaufenthalt
-
Bewerbung
- Auswahlgrenzen und Vergabeverfahren (NC)
- Bewerbungsportal
- Bewerbung Schritt für Schritt: Von der Bewerbung bis zur Einschreibung
- Bewerbung für ein höheres Fachsemester
- Bewerbung mit beruflicher Qualifikation
- Gasthörerschaft und Zweithörerschaft
- Kontakt Studierendenservice
- Losverfahren
- Promotion
- Sonderanträge
- Studiengang wählen
- Wer kann an der HSBI studieren?
- Studienstart
-
Studium organisieren
- Studierendenservice
- Abschlussunterlagen
- Anerkennung von Leistungen
- Anträge einreichen
- Beurlaubung
- CampusCard
- Einreichung schriftliche Arbeiten
- Exmatrikulation
- IT-Services
- Online-Serviceportale (LSF/CAT)
- Prüfungsangelegenheiten: Ordnungen, Modulhandbücher
- Rücktritt von einer Modulprüfung
- Rückmeldung
- Semesterbeitrag
- Semesterticket (Studi-Deutschlandticket)
- Semester- und Vorlesungszeiten
- Studienbezogene Auslandserfahrung
- Studiengebühren
- Vorlesungsverzeichnis
- Rund ums Studium
- Fachbereiche

- Forschung
- Transfer
- Weiterbildung
- Internationales
- Karriere an der HSBI
Interpretierbare und übertragbare KI für StarCraft2
Projektübersicht
| Anzahl Studierende | 1-3 |
| Projektverantwortung | Prof. Dr. Christian Schwede |
| Projektkontext | Das Studienprojekt ist am Digital Labor des Campus Gütersloh angesiedelt. Das Team besteht aus einem Wissenschaftlichem Mitarbeiter und zwei weiteren Studierenden. |
| Projektdurchführung | Philip Scheidig |
Kurzbeschreibung
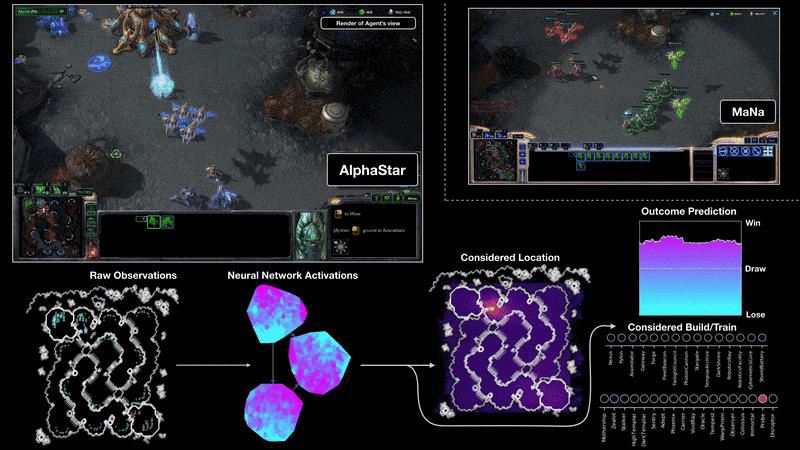
Computerspiele stellen schon seit den Anfängen der Künstlichen Intelligenz eine spannende Herausforderung für die Entwicklung von Intelligenten Agenten dar. Große Durchbrüche der KI-Forschung zeigten sich häufig durch die Entwicklung von Programmen, die in der Lage waren menschliche Gegenspieler zu besiegen. Deep Blue schlug 1996 den amtierenden Weltmeister Kasparow im Schach, IBMs Watson gewinnt 2011 in „Jeopardy!“ gegen zwei gegen zwei Profis und Googles AlphaGo schlägt 2016 Lee Sedol einen der weltbesten Go-Spieler. Seit 2019 spielt Deepminds AlphaStar in den diversen Ligen von Starcraft2 und besiegt mittlerweile 99,8% der Spieler. Auch wenn diese KI hinsichtlich der Performanz unübertroffen ist, so erfüllt sie zwei andere wichtige Anforderungen an KI kaum: Übertragbarkeit/Lerneffizienz und Erklärbarkeit. Auf dem Weg zur Starken KI ist die Lerneffizienz bzw. die Übertragbarkeit und das nicht Vergessen von Wissen entscheidend, während für uns Menschen der Einblick in das Was und Warum des Handels von KI von entscheidender Bedeutung ist.
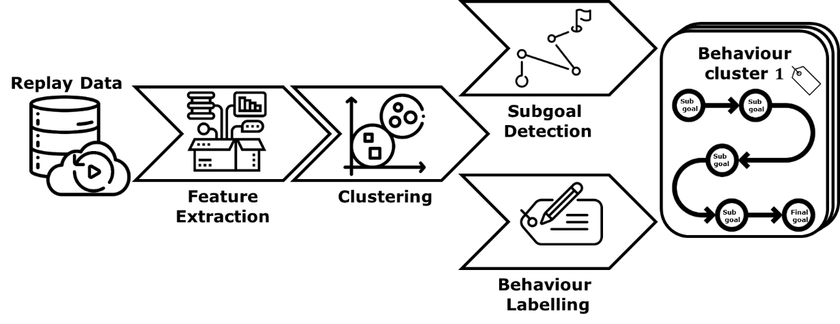
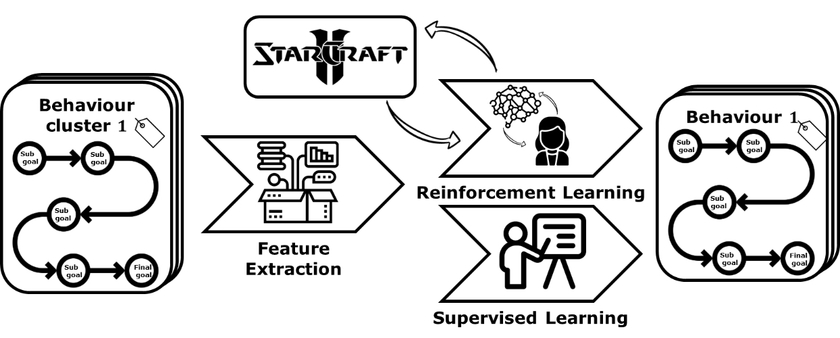
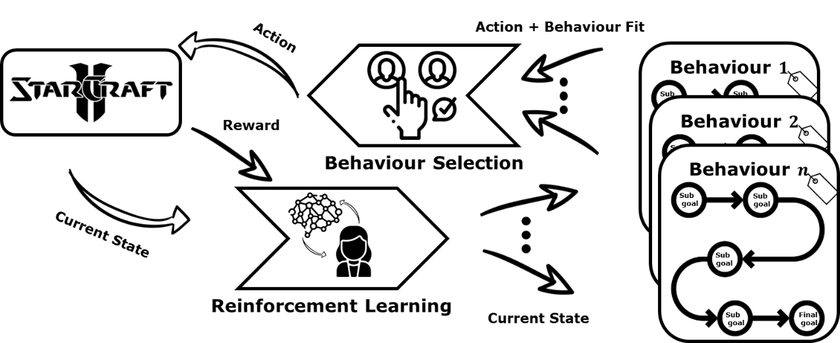
In diesem Projekt wird deshalb an einer Künstlichen Intelligenz für StarCraft2 gearbeitet die diese beiden Anforderungen erfüllt. Die Grundidee ist es eine KI zu entwickeln die lernt je nach Situation einen passenden Handlungsbaustein (Strategie) und nicht nur eine einzelne Aktion auszuwählen. So kann Wissen in den Bausteinen bewahrt werden und komplexe Handlungen durch die Kapselung in Strategien erklärbarer werden. Hierbei sollen die einzelnen Strategiebausteine auf Basis von Beispielpartien erst erkannt und dann gelernt werden. Durch die zusätzliche Konstruierung eines Subziel-Graphen, der die Zwischenziele einzelner Strategiebausteine in Reihenfolge bringt, werden diese dann für Menschen nochmal erklärbarer. Der gesamte Ansatz ist in drei Teilschritte unterteilt und in folgender Grafik dargestellt. Als erstes werden aus Beispieldaten Strategiecluster mittels Zeitreihenclusterings gelernt, dann wird auf Basis von diesen Clustern mittels Supervised oder Reinforcement Learning Strategiebausteine gelernt und schließlich findet mittels Hierarchical Reinforcement Learning die High-Level Strategie gelernt.

Aufgabenbeschreibung des Studierenden
Die Studierenden können je nach Interesse in einem der oben beschrieben Teilbereiche arbeiten. Der Schwerpunkt der Arbeit kann dabei einen der drei genannten Verfahrensgruppen betreffen.
Der erste Bereich der Strategieerkennung wird hauptsächlich mit Clusterverfahren arbeiten. Aufgaben der Merkmalsextraktion im variablen und hochdimensionalen Eingaberaum von StarCraft2, der Auswahl von passenden Distanzmetriken, die Auswahl und Implementierung von Clusterverfahren für variable Zeitreihen, der Entwicklung von Verfahren für die Erkennung von Teilzielen und das automatische Labelling können bearbeitet werden.
Der zweite Bereich kann entweder Verfahren des Supervised oder des Deep Reinforcement Learnings umfassen. Überwachte Verfahren werden genutzt, um das Verhalten der geclusterten Strategien nachzuahmen, während Verstärkendes Lernen ein eigenes Verhalten anhand der Subgoals lernen soll.
Der Dritte Bereich umfasst Verfahren des Hierarchical Reinforcement Learnings. Hierbei muss erlernt werden den passenden Strategiebaustein für die jeweilige Situation auszuwählen. Außerdem muss das Auswahlverhalten derart beeinflusst werden, dass die Strategie nicht nach jeder Aktion neu gewählt wird.
Bezug zum Thema Data Science
Verfahren des Clustering, Supervised und Reinforcement Learning sind Kernthemen der Data Science und werden auch in den Veranstaltungen des Forschungsmasters behandelt.
Verfügbare Ressourcen
- Millionen von Replay-Daten und eine Python-API für StarCraft2 stehen zur Verfügung
- Hardware für das Maschine Learning ist über das Data Science Lab oder das CfADS der HSBI verfügbar
Projektplan
- Erstes Semester: Formulierung des Forschungsexposees, Einarbeitung in das Spiel, den Source Code und die API.
- Zweites Semester: Entwicklung eines einfachen Algorithmus in dem jeweiligen Feld für ein einfaches Spieleszenario, Recherche zu relevanten Arbeiten im Themenfeld
- Drittes Semester: Entwicklung von ersten komplexeren Verfahren für einfachere und komplexere Spielszenarien, Auswertung erster Ergebnisse
- Viertes Semester: Erstellung eines komplexen Szenarios, Implementierung und Vergleich von weiteren Verfahren, Fine-Tuning und Optimierung der Verfahren, Verbesserung der Ergebnisse, Finale Evaluierung
Eignungskriterien
Zwingend:
- Programmierkenntnisse
- Begeisterung für Spiele/ StarCraft2 und KI
Optional:
- Erfahrung in der ML
Erwerbbare Kompetenzen
Einsatz und (Weiter-)Entwicklung von State-of-the-Art Verfahren des Maschinellen Lernens in hochkomplexen Umgebungen.